In this post, we build a model that provides end-to-end capability of detecting faces from image and predicting the BMI, Age and Gender for each detected persons.
The model is made up by several parts:
- input pre-processing pipeline:
- load the image, resize to 224 x 224 and convert to array, which forms the features (
X) - map the labels (
y: {BMI, Age, Gender}) from meta-data - random sample from train and valid dataset to build the
generatorfor model fitting
- load the image, resize to 224 x 224 and convert to array, which forms the features (
- face detector (
MTCNN):- alignment: pre-process the training data by cropping the detected faces
- detect: when applying the model, detect the bounded faces from input picture and then apply the model for predictions.
- face prediction (
VGGFace):- transfer learning from
VGGFace, with VGG16 and ResNet50 backbones - multi-task learning to learn 3 tasks together
- transfer learning from
The architecture of the model is described as below:

Face detection
Face detection is done by MTCNN, which is able to detect multiple faces within an image and draw the bounding box for each faces.
It serves two purposes for this project:
1) pre-process and align the facial features of image.
Prior model training, each image is pre-processed by MTCNN to extract faces and crop images to focus on the facial part. The cropped images are saved and used to train the model in later part.
Illustration of face alignment:

2) enable prediction for multiple persons in the same image.
In inference phase, faces will be detected from the input image. For each face, it will go through the same pre-processing and make the predictions.
Illustration of ability to predict for multiple faces:
Multi-task prediction
In vanilla CNN architecture, convolutional blocks are followed by the dense layers to output the prediction. In a naive implementation, we can build 3 models to predict BMI, age and gender individually. However, there is a strong drawback that 3 models are required to be trained and serialized separately, which drastically increases the maintenance efforts.
[input image] => [VGG16] => [dense layers] => [BMI]
[input image] => [VGG16] => [dense layers] => [AGE]
[input image] => [VGG16] => [dense layers] => [SEX]
Since we are going to predict BMI, Age, Sex from the same image, we can share the same backbone for the three different prediction heads and hence only one model will be maintained.
[input image] => [VGG16] => [separate dense layers] x3 => weighted([BMI], [AGE], [SEX])
This is the most simplified multi-task learning structure, which assumed independent tasks and hence separate dense layers were used for each head. Other research such as Deep Relationship Networks, used matrix priors to model the relationship between tasks.
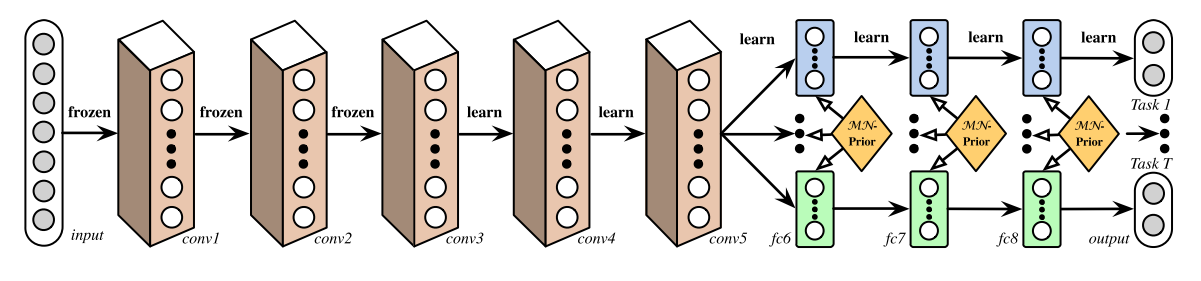 A Deep Relationship Network with shared convolutional and task-specific fully connected layers with matrix priors (Long and Wang, 2015).
A Deep Relationship Network with shared convolutional and task-specific fully connected layers with matrix priors (Long and Wang, 2015).
Dataset
The data used for training was crawled from web. The details of the web-scraping works are recorded in this post: web-scraping-of-javascript-website. This is fairly small dataset, which comprises 1530 records and 16 columns.
A very brief EDA was done to get the summary of data:
- sex imbalance: 80% of the data is male
- age is near truncated normal distribution. min Age is 18, average Age is 34.
- race is dominated by Black and White. Asian samples are very limited.
- BMI is normal distributed, with mean at 26.
- no obvious correlation found between BMI and Age, Sex.
allimages = os.listdir('./face_aligned/')
train = pd.read_csv('./train.csv')
valid = pd.read_csv('./valid.csv')
train = train.loc[train['index'].isin(allimages)]
valid = valid.loc[valid['index'].isin(allimages)]
data = pd.concat([train, valid])
data[['age','race','sex','bmi','index']].head()

fig, axs = plt.subplots(1,4)
fig.set_size_inches((16, 3))
axs[0].barh(data.sex.unique(), data.sex.value_counts())
axs[0].set_title('Sex Distribution')
axs[1].hist(data.age, bins = 30)
axs[1].set_title('Age Distribution')
axs[2].hist(data.bmi, bins = 30)
axs[2].set_title('BMI Distribution')
axs[3].barh(data.race.unique(), data.race.value_counts())
axs[3].set_title('Race Distribution')
plt.tight_layout()

fig, axs = plt.subplots(1,3)
fig.set_size_inches((16, 4))
for i in ['Male','Female']:
axs[0].hist(data.loc[data.sex == i,'bmi'].values, label = i, alpha = 0.5, density=True, bins = 30)
axs[0].set_title('BMI by Sex')
axs[0].legend()
res = data.groupby(['age','sex'], as_index=False)['bmi'].median()
for i in ['Male','Female']:
axs[1].scatter(res.loc[res.sex == i,'age'].values, res.loc[res.sex == i,'bmi'].values,label = i, alpha = 0.5)
axs[1].set_title('median BMI by Age')
axs[1].legend()
for i in ['Black','White','Asian']:
axs[2].hist(data.loc[data.race == i,'bmi'].values, label = i, alpha = 0.5, density=True, bins = 30)
axs[2].set_title('BMI by Race')
axs[2].legend()
plt.show()

Model training
A model class FacePrediction was built separately from the notebook. Please refer to here for the details of model.
es = EarlyStopping(patience=3)
ckp = ModelCheckpoint(model_dir, save_best_only=True, save_weights_only=True, verbose=1)
tb = TensorBoard('./tb/%s'%(model_type))
callbacks = [es, ckp, tb]
model = FacePrediction(img_dir = './face_aligned/', model_type = 'vgg16')
model.define_model()
model.model.summary()
if mode == 'train':
model.train(train, valid, bs = 8, epochs = 20, callbacks = callbacks)
else:
model.load_weights(model_dir)
Model evaluation
The performance of tested models are quite similar. What surprised me is that, ResNet50 doesn’t outperform VGG16.
Note: VGG16_fc6 is the model that uses VGG16 as backbone, but extracted features from layer fc6 instead of the last convolutional layer. This is recommended setting from this paper: Face-to-BMI: Using Computer Vision to Infer Body Mass Index on Social Media.


Model Predictions
the built model class FacePrediction provides different predict functions
- predict: apply to either single image or a directory, and make subplots
- predict_df: predict from a directory and output as a pandas dataframe
- predict_faces: detect faces and predict for all faces
predict from directory:
preds = model.predict('./test_aligned/', show_img = True)

predict multiple faces:
preds = model.predict_faces('./test_mf/the-big-bang-theory-op-netflix.jpg', color = 'red')

predictions from different models:
Code:
the notebook is available at here
the complete code is available at here