Introduction
In this post, I’m using selenium to demonstrate how to web scrape a JavaScript enabled page.
Why not Beautiful Soup ?
If you had some experience of using python for web scraping, you probably already heard of beautifulsoup and urllib. By using the following code, we will be able to see the HTML and then use HTML tags to extract the desired elements. However, if the web page embedded with JavaScript, you will notice that some of the HTML elements can’t be seen from the beautiful soup, because they are rendered by the JavaScript. Instead you will only see the script tags, which indicate the place where the JavaScript codes are placed.
urlpage = 'https://apps.polkcountyiowa.gov/PolkCountyInmates/CurrentInmates/' # download the web page f = urllib.request.urlopen(urlpage) # extract the html text html = f.read() # parse html using beautifulsoup bs = BeautifulSoup(html)
the desired html elements are rendered by the script tags, so an alternative is needed to extract this page. 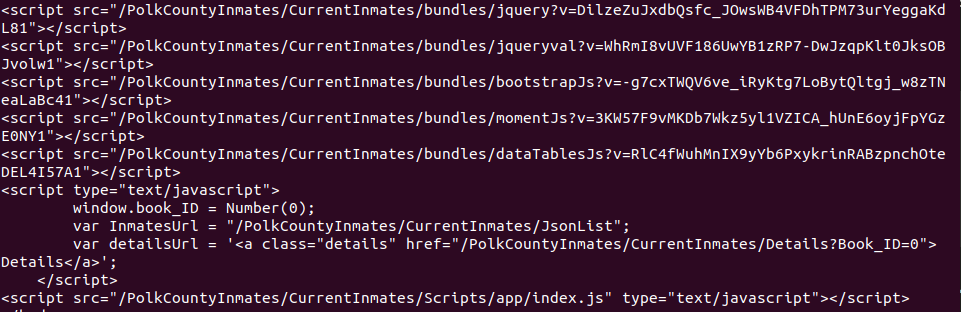
Procedures of Web-Scraping using Selenium
1. Prerequisite
- download the chrome driver from https://chromedriver.chromium.org/downloads
- current stable version is 76.0.3809.126
- choose your Operating System (Mac/Windows/Linux)
- extract the webdriver to
CHOME_DRIVER(e.g../chromedriver)
2. Launch the Chrome Driver
use selenium to launch the a chrome browser, by calling webdriver.Chrome(). A blank chrome window should pop up.
from selenium import webdriver CHROME_DRIVER = './chromedriver' # run chrome webdriver from executable path of your choice driver = webdriver.Chrome(executable_path = CHROME_DRIVER)
Now, let’s load the page we want to extract.
# load web page
urlpage = 'https://apps.polkcountyiowa.gov/PolkCountyInmates/CurrentInmates/'
driver.get(urlpage)
print('waiting 15s for page loading')
# wait for 15 seconds to allow the page completely loaded
time.sleep(15)
use driver.quit() to close the browser when you are done with testing.
3. Parse the Web Page
selenium provides multiple ways to locate the elements of the HTML. By using Chrome Developer Tools (Chrome > More tools > Developer tools), we can easily locate the HTML elements. For example, we’re going to extract the link of Details, so we point the HTML element and copy the xpath location.
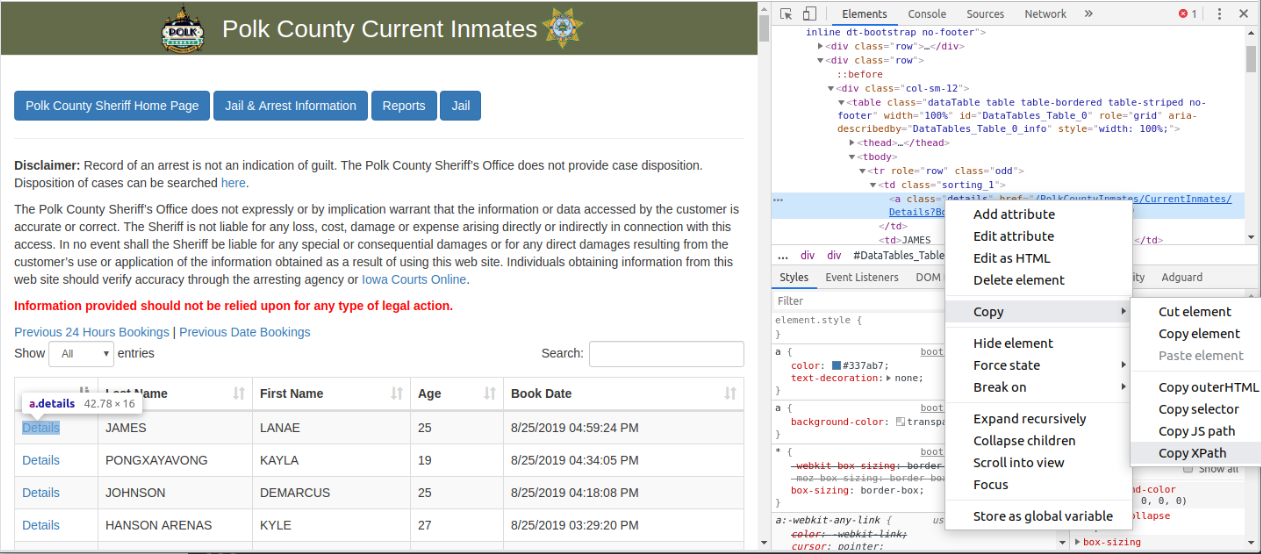
In selenium, we can call find_elements_by_xpath to extract all elements that matching the xpath pattern.
xpath = '//*[@id="DataTables_Table_0"]/tbody/tr[1]/td[1]/a'
results = driver.find_elements_by_xpath(xpath)
# results is a list, because find_elements_by_xpath look for all items matching the xpath.
# if use find_element_by_xpath, it returns the first item matches the xpath.
len(results)
# 1
results[0].get_attribute('href')
# https://apps.polkcountyiowa.gov/PolkCountyInmates/CurrentInmates/Details?Book_ID=299591
It’s worth noticing that, the xpath pattern is too specific and only the first link is returned. Therefore we need to generalize the xpath pattern, to capture all the links.
Let’s trace back to the upper levels of the xpath. Instead of using tr[1] to extract the first row, we use *[contains(@role,'row')] to capture all the rows contains the class role='row'.
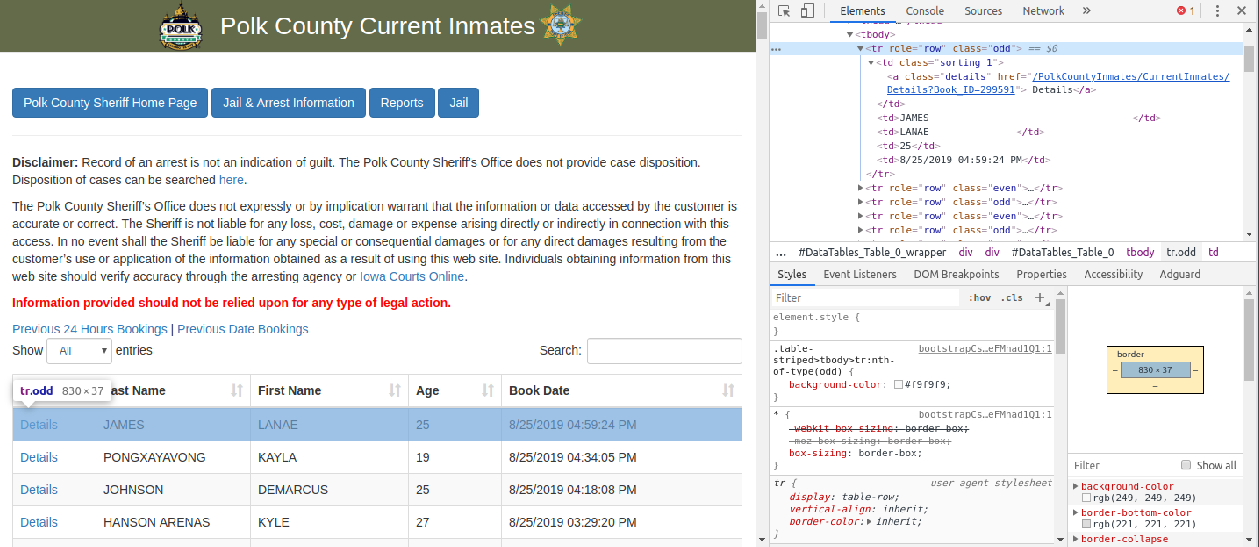
Then in each element, we use td/a xpath to locate the html a tags. Because the number of links is relative big, a tqdm progress bar is also added to show the progress of extraction.
xpath = "//*[@id='DataTables_Table_0']/tbody//*[contains(@role,'row')]"
results = driver.find_elements_by_xpath(xpath)
len(results)
# 938
results[0].find_element_by_xpath('td/a').get_attribute('href')
# https://apps.polkcountyiowa.gov/PolkCountyInmates/CurrentInmates/Details?Book_ID=299591
# add progress bar to extract all links
from tqdm import tqdm
links = []
for result in tqdm(results):
links.append(result.find_element_by_xpath('td/a').get_attribute('href'))
4. save the data
Finally, we can save the links to a csv file for later usage.
import pandas as pd
df_links = pd.DataFrame({'links':links})
# save data to csv
df_links.to_csv('./links.csv', index = False)
# close the browser
driver.quit()
The complete code is stored at here

One thought on “Web Scraping of JavaScript website”