
Introduction
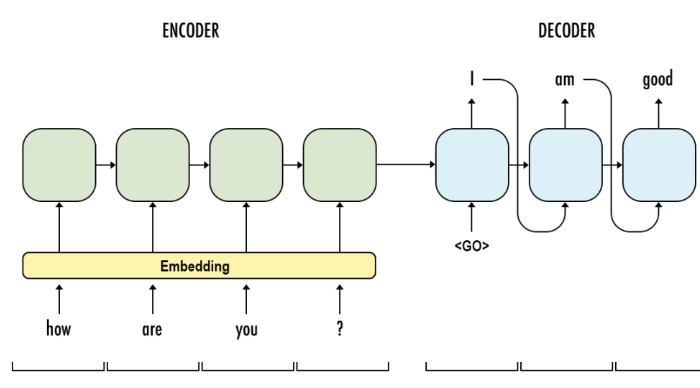
seq2seq model is a general purpose sequence learning and generation model. It uses encoder decoder architecture, which is widely wised in different tasks in NLP, such as Machines Translation, Question Answering, Image Captioning.
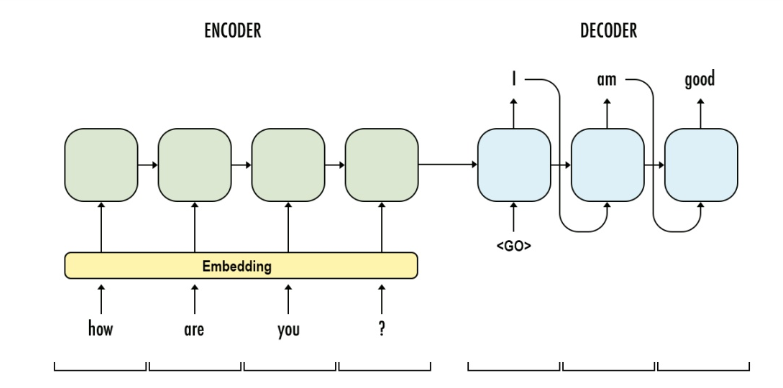
The model consists of major components:
Embedding: using low dimension dense array to represent discrete word token. In practice, a word embedding lookup table is formed with shape (vocab_size, latent_dim) and initialized with random numbers. Then each individual word will look up the index and take the embedding array to represent itself.
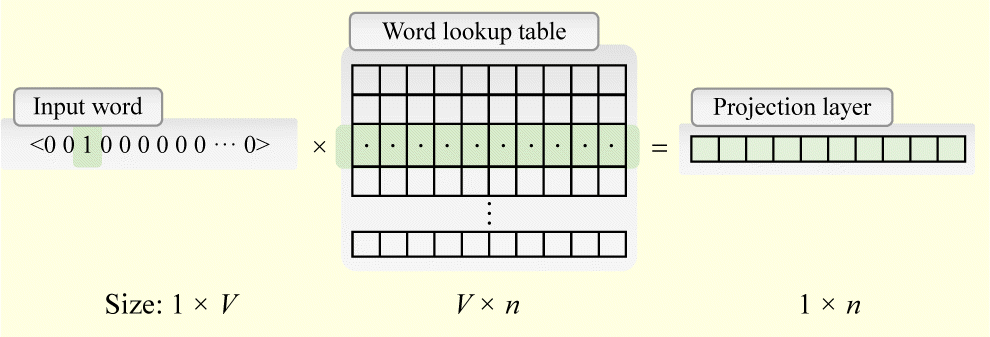
Let’s say, if the input sentence is “see you again”, which may be encoded as a sequence of [100, 21, 24]. Each value is the index in the work lookup table. After embedding lookup, the sequence [100, 21, 24] will be converted to [W[100,:], W[21,:], W[24,:]], with W as the word lookup table.
RNN: captures the sequence of data and formed by a series of RNN cells. In neural machine translation, RNN can be either LSTM or GRU.
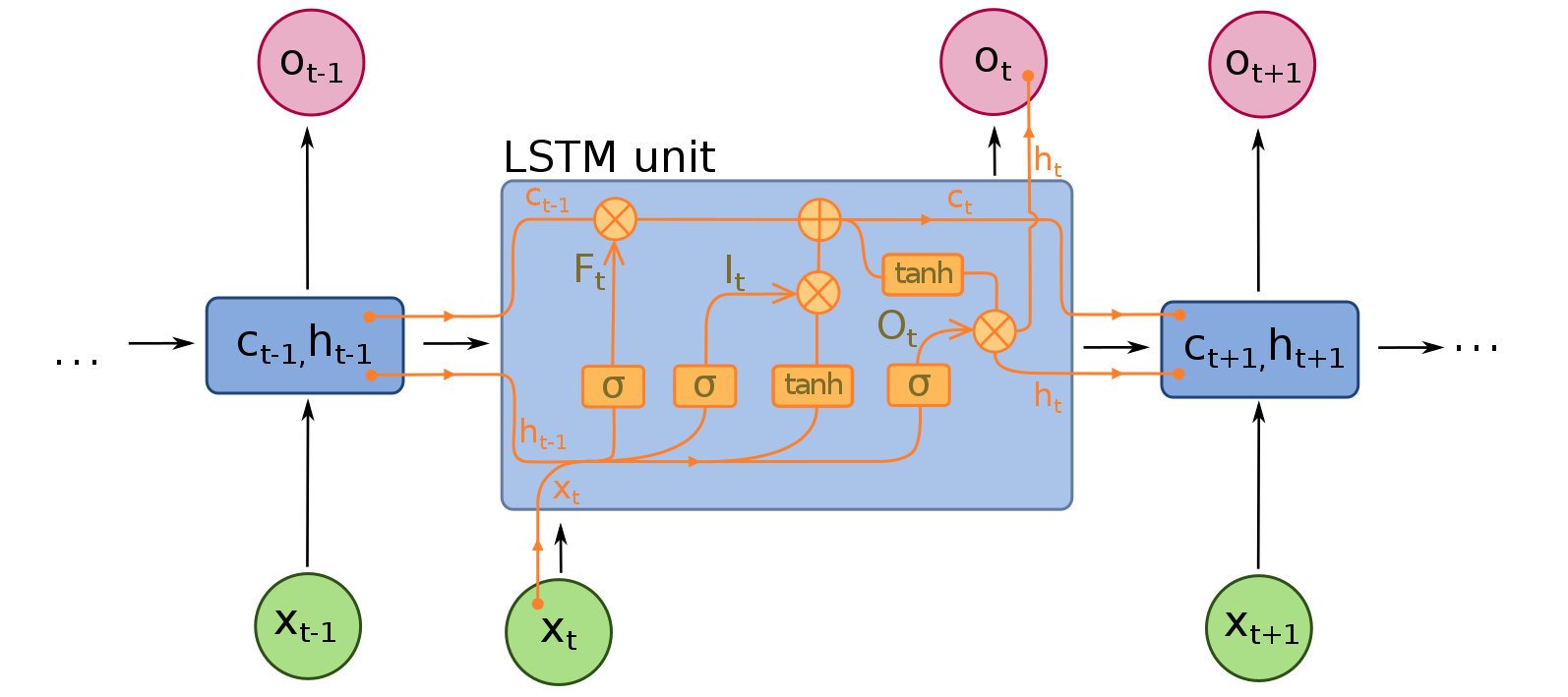
- t refers to the sequence of the words/tokens.
- x is the input of RNN, refers to the embedding array of the word
- c, h refer to the hidden states from LSTM cells, which is migrating throughout the RNN
- o is the output array, used to map to the predictions
Encoder: is the a RNN with input as source sentences. The output can be the output array at the final time-step (t) or the hidden states (c, h) or both, depends on the encoder decoder framework setup. The aim of encoder is to capture or understand the meaning of source sentences and pass the knowledge (output, states) to encoder for prediction.
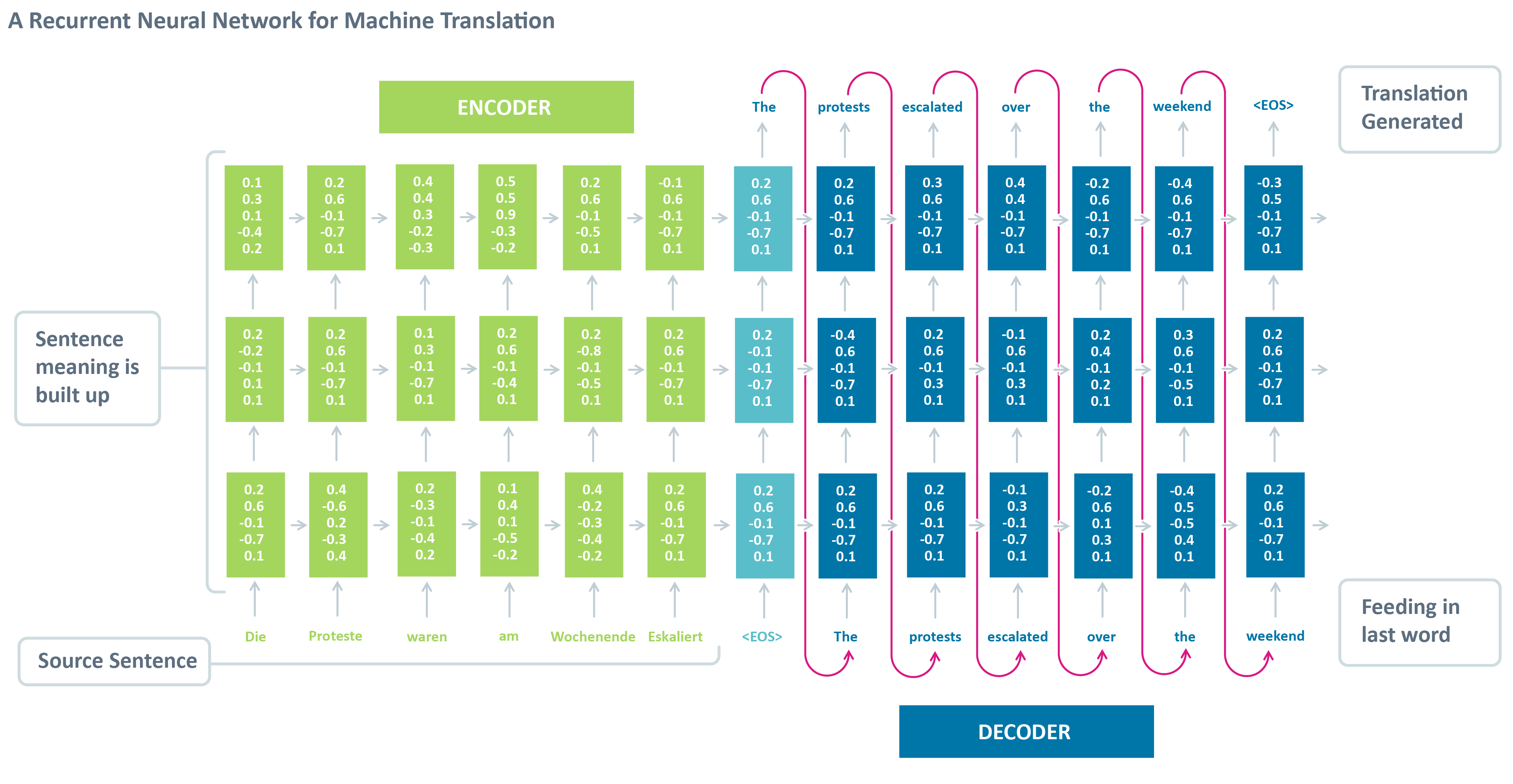
Decoder: is another RNN with input as target sentences. The output is the next token of target sentence. The aim of decoder is to predict the next word, with a word given in the target sentence.
steps to train a seq2seq model:
- Word/Sentence representation: this includes tokenize the input and output sentences, matrix representation of sentences, such as TF-IDF, bag-of-words.
- Word Embedding: lower dimensional representation of words. With a sizeable corpus, embedding layers are highly recommended.
- Feed Encoder: input source tokens/embedded array into encoder RNN (I used LSTM in this post) and learn the hidden states
- Connect Encoder & Decoder: pass the hidden states to decoder RNN as the initial states
- Decoder Teacher Forcing: input the sentence to be translated to decoder RNN, and target is the sentences which is one word right-shifted. In the structure, the objective of each word in the decoder sentence is to predict the next word, with the condition of encoded sentence and prior decoded words. This kind of network training is called teacher forcing.
However, we can’t directly use the model for predicting, because we won’t know the decoded sentences when we use the model to translate. Therefore, we need another inference model to performance translation (sequence generation).
steps to infer a seq2seq model:
- Encoding: feed the processed source sentences into encoder to generate the hidden states
- Decoding: the initial token to start is <s>, with the hidden states pass from encoder, we can predict the next token.
- Token Search:
- for each token prediction, we can choose the token with the most probability, this is called greedy search. We just get the best at current moment.
- alternatively, if we keep the n best candidate tokens, and search for a wider options, this is called beam search, n is the beam size.
- the stop criteria can be the <e> token or the length of sentence is reached the maximal.
demo of English-Chinese translation
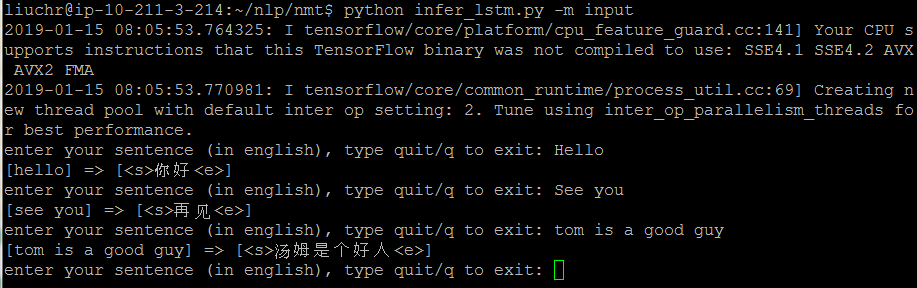
- github repo: https://github.com/6chaoran/nlp/tree/master/nmt
- jupyter notebook: https://github.com/6chaoran/nlp/blob/master/nmt/infer_lstm.ipynb
Continue reading “Build a machine translator using Keras (part-1) seq2seq with lstm”
